9月24日,2025云栖大会现场,阿里云CTO周靖人接连发布了七款大模型技术产品。七款技术产品覆盖语言、语音、视觉、多模态、代码等领域,在智能水平、工具调用以及编码能力、深度推理、多模态等方面均实现突破。

在大语言模型领域,阿里通义旗舰模型Qwen3-Max全新亮相,性能位列全球前三,超过GPT-5与 Claude OpUS 4 等。Qwen3-Max包含指令版和推理版两大版本,其预览版已在Chatbot Arena排行榜上名列第三,正式版本有望进一步突破。
Qwen3-Max是通义千问家族中最大、最强的基础模型,预训练数据量达36TB,总参数超过万亿,具备强大的编码与工具调用能力。在SWE-Bench Verified测试中,InstRuct版本获69.6分,全球领先;在Tau2-Bench测试中,Qwen3-Max获74.8分,超过Claude OpUS4与DeepSeek-V3.1。推理性能突出,结合工具调用和并行推理,在数学推理测试中达到满分100分,为国内首次。
下一代基础模型架构Qwen3-Next及系列模型发布,模型总参数80B,激活3B,性能可媲美235B旗舰版,显著提升计算效率。设计面向扩展趋势,采用混合注意力、高稀疏MoE、多Token预测等核心技术,训练成本下降超90%,长文本推理吞吐量提升十倍以上,为未来大模型训练与推理设立新标准。
在专项模型方面,Qwen3-codeR升级。新的Qwen3-codeR与Qwen code、Claude code系统联合训练,推理速度更快,代码安全性提升。此前Qwen3-codeR广受好评,代码生成与补全能力出众,可一键完成完整项目的部署与问题修复,开源后调用量在OpenRouteR平台曾显著增长,位列全球第二。
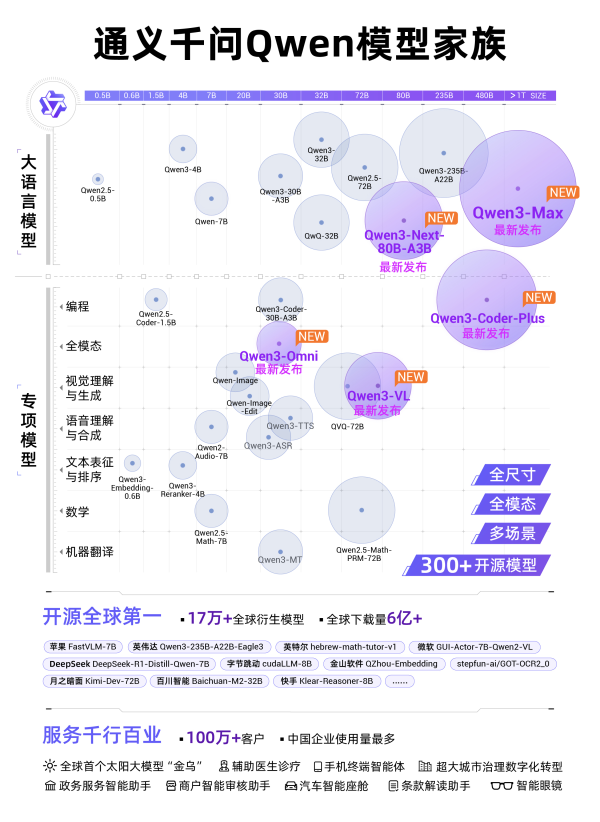
通义千问Qwen模型家族图
在多模态模型领域,Qwen3-VL重磅开源,在视觉感知与多模态推理方面的核心能力评测中领先,包括超越GeMini2.5-Pro和GPT-5。在视觉智能和视觉编码方面,Qwen3-VL不仅能理解图片,还能像人一样操作设备,自动完成日常任务。输入图片后可调用agent放大细节,或生成Draw.io/HTML/CSS/JS 代码,所见即所得地完成视觉编程。此外,Qwen3-VL还升级了3D grounding能力,支持更大上下文与更长视频理解。
全模态模型Qwen3-OMni首次亮相,音视频能力在开源领域达到多项最佳性能,可像人一样听说写,应用场景覆盖车载、智能眼镜、手机等。用户可设定个性化角色、调整对话风格,打造个人IP。通过混合单模态与跨模态的预训练,具备多模态协同能力,且在单模态文本与图像性能保持稳定,这是业内的突破性训练成果。
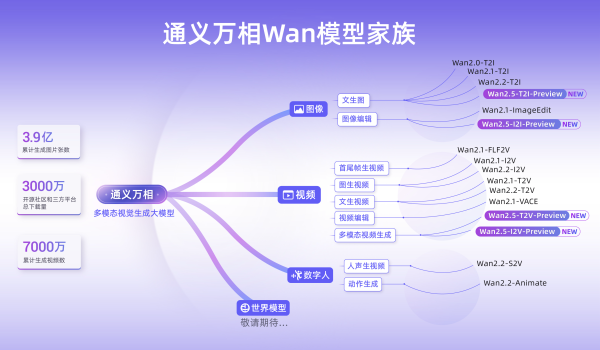
通义万相Wan模型家族图
通义万相是通义大模型家族中的视觉基础模型,此次推出Wan2.5-pReview系列,覆盖文生视频、图生视频、文生图与图像编辑四大模型。Wan2.5视频生成能搭配画面输出人声、音效与背景音乐,首次实现音画同步的视频生成,降低电影级制作门槛。视频生成时长从5秒提升至10秒,支持1080P、24帧每秒的视频,进一步提升模型对指令的遵循能力。Wan2.5还全面升级了图像生成,能输出中英文文本和图表,支持图像编辑,一句话即可完成P图。

阿里云CTO周靖人发布通义百聆
云栖大会上,通义大模型家族迎来新成员——语音大模型通义百聆。百聆发布了语音识别大模型Fun-ASR和语音合成大模型Fun-CosyVoice。Fun-ASR基于大量真实语音数据训练,具备强大的上下文理解与行业适应性;Fun-CosyVoice提供百余种音色,适用于客服、销售、直播电商、消费电子、有声书等场景。
从0.5B到万亿级,通义大模型覆盖全尺寸,涵盖LLM、编程、图像、语音、视频等全模态,满足从终端到云端的多场景需求。自2023年开源以来,通义大模型全球下载量超过6亿,衍生模型超17万个,成为全球第一开源模型。除了支持AI开发者,通义衍生模型的开发机构还包括苹果、英伟达、微软、DeepSeek、字节跳动等。截至目前,通义大模型已服务超过100万客户。沙利文报告显示,2025年上半年,通义在中国企业级大模型调用市场居第一。

