
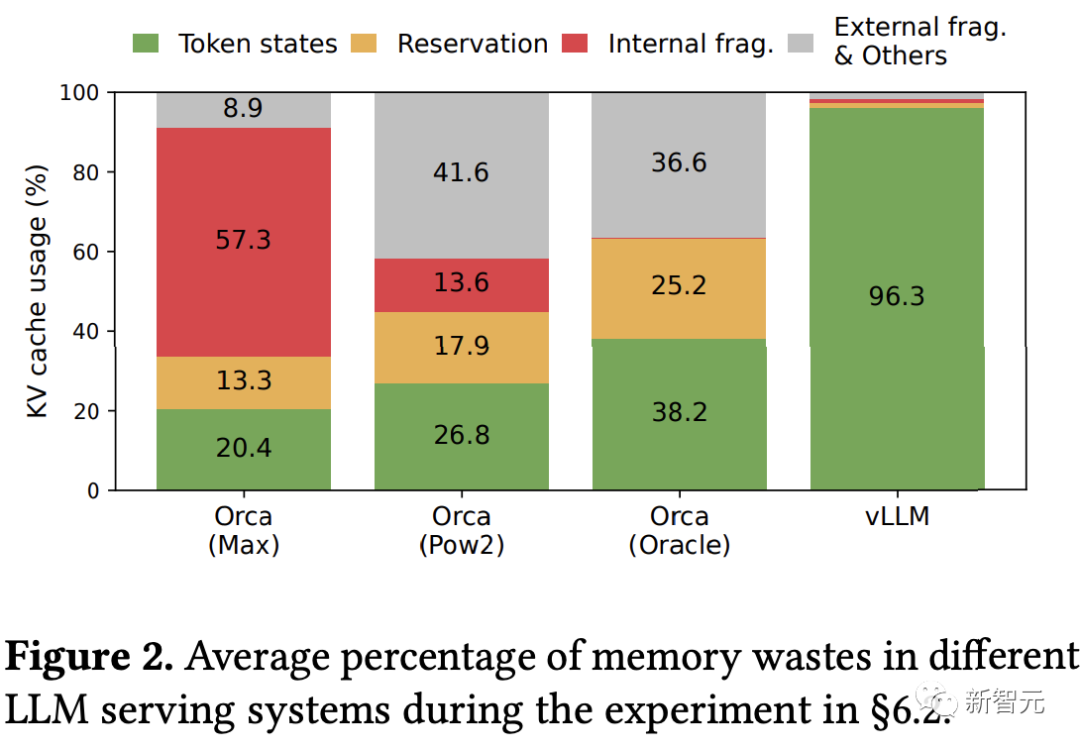
打造高吞吐量的LLM服务,需要模型在一个批次内处理尽可能多的请求,现有系统大多在每次处理请求时申请大量的key-value(KV)缓存,管理效率不高,大量内存会被浪费,限制了batch size的增长。

加州大学伯克利分校、斯坦福大学、加州大学圣迭戈分校的研究人员基于虚拟内存和分页技术,提出了一个新的注意力算法PagedAttention,并打造了一个LLM服务系统vLLM

论文链接:https://arxiv.org/pdf/2309.06180.pdf
开源链接:https://github.com/vllm-project/vllm
vLLM在KV缓存上实现了几乎零浪费,并且可以在「请求内部」和「请求之间」灵活共享KV高速缓存,进一步减少了内存的使用量。
vLLM可以将常用的LLM吞吐量提高了2-4倍,在延迟水平上与最先进的系统(如FasterTransformer和Orca)相当,在更长序列、更大模型和更复杂的解码算法时,提升更明显。
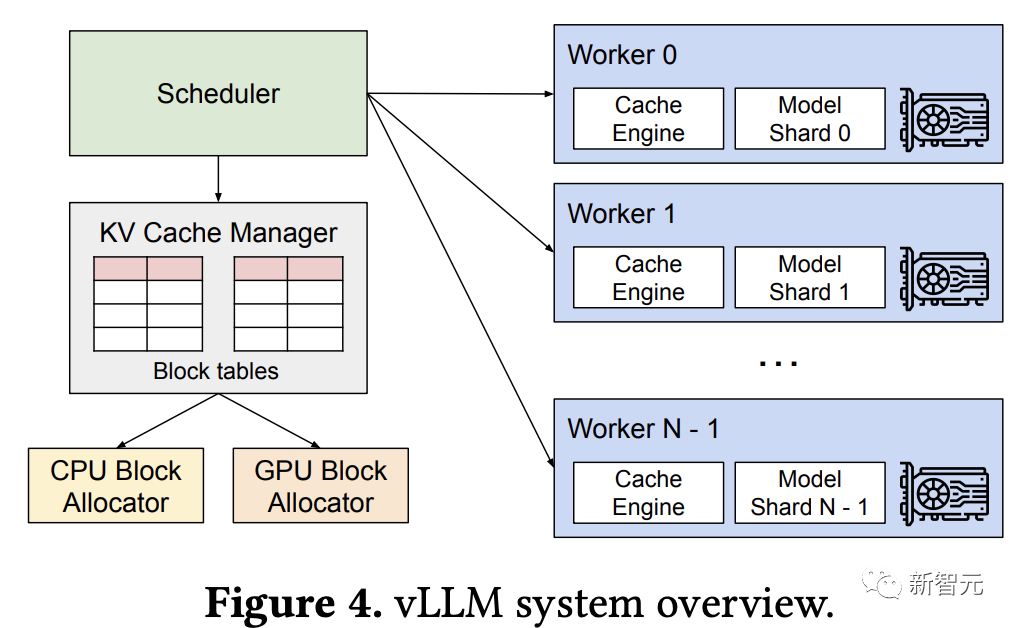
研究人员开发了一种全新的注意力算法PagedAttention,并构建了一个LLM服务引擎vLLM,采用集中式调度器来协调分布式GPU工作线程的执行。
1. 算法
PagedAttention将序列中KV缓存划分为KV块,每个块包含固定数量tokens的键(K)和值(V)向量,将注意力计算转换为块级运算:
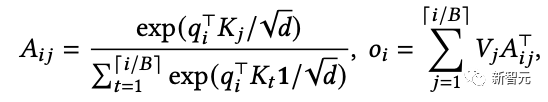
在注意力计算期间,PagedAttention内核识别和获取不同的KV块,将查询向量与块中的键向量相乘得到部分注意力得分,再乘以块中的值向量得到最终注意力输出。

这种设计使得KV块存储在非连续物理内存中,让vLLM中的分页内存管理更加灵活。
2. KV缓存管理器
操作系统将内存划分为多个固定大小的页,并将用户程序的逻辑页映射到物理页,连续的逻辑页可以对应于非连续的物理内存页,用户在访问内存时看起来就像连续的一样。
物理内存空间不需要提前完全预留,使操作系统能够根据需求动态分配物理页。
vLLM利用虚拟内存机制将KV缓存表示为一系列逻辑KV块,在生成新token及KV缓存时,从左到右进行填充;最后一个KV块的未填充位置预留给后续生成操作。
KV块管理器还负责维护块表(block table),每个请求的逻辑和物理KV块之间的映射。
将逻辑和物理KV块分离使得vLLM能够动态地增长KV高速缓存存储器,无需预先保留给所有位置,消除了现有系统中的大多数内存浪费。
3. 解码
vLLM在单个输入序列的解码过程中执行PagedAttention并管理内存。
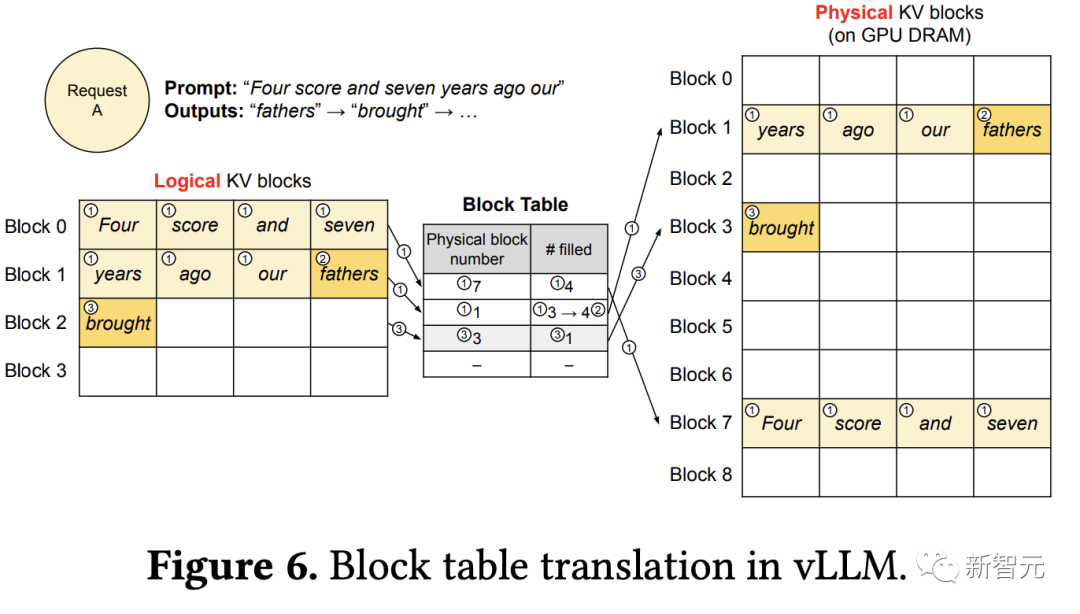
① vLLM最初不需要为最大可能生成的序列长度预留内存,只保留必要的KV块,以容纳在即时计算期间生成的KV缓存。
提示词中包含7个tokens,vLLM将前两个逻辑KV块映射到2个物理KV块;在预填充步骤中,vLLM使用自注意算法生成提示和首个输出token的KV缓存;然后将前4个token的KV缓存存储在逻辑块0中,后面3个token存储在逻辑块1中;剩余的slot被保留用于后续自回归生成。
② 在首个自回归解码步骤中,vLLM在物理块7和1上使用PagedAttention算法生成新token
由于最后一个逻辑块中仍有一个slot可用,将新生成的KV缓存存储在该slot,更新块表的#filled记录。
③ 在第二次解码步骤中,当最后一个逻辑块已满时,vLLM将新生成的KV缓存存储在新的逻辑块中,为其分配一个新的物理块(物理块3),并映射存储在块表中。
在LLM的计算过程中,vLLM使用PagedAttention内核访问以前以逻辑KV块形式存储的KV缓存,并将新生成的KV缓存保存到物理KV块中。
在一个KV块中存储多个token使PagedAttention内核能够跨更多位置并行处理KV缓存,提高硬件利用率并减少延迟,但较大的块大小也会增加内存碎片。
4. 通用解码
支持单个用户提示输入生成单个输出序列等基本场景,该算法还支持更复杂的解码场景,如并行采样、集束搜索、共享前缀等。
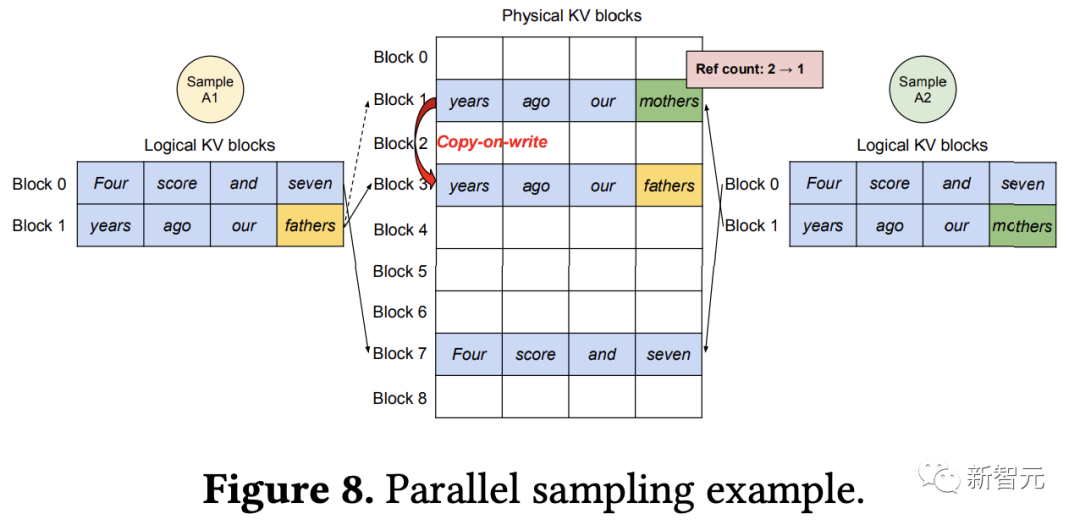
5. 调度和抢占(Scheduling and Preemption)
当请求流量超过系统容量时,vLLM必须对请求子集进行优先级排序,具体采用「先来先服务」的调度策略,确保公平性并防止饥饿。
LLM的输入提示在长度上可能变化很大,输出长度是先验未知的,取决于输入提示和模型;随着请求及其输出数量的增长,vLLM可能会耗尽GPU的物理块来存储新生成的KV缓存。
交换是大多数虚拟内存算法使用的经典技术,将被释放的页复制到磁盘上的交换空间。
除了GPU块分配器,vLLM还包括CPU块分配器,管理交换到CPU RAM的物理块;当vLLM耗尽新令牌的空闲物理块时,选择一组序列来释放KV缓存并将其传输到CPU。
在这种设计中,交换到CPU RAM的块数永远不会超过GPU RAM中的物理块总数,因此CPU RAM上的交换空间受到分配给KV缓存的GPU内存的限制。
重新计算,被抢占的序列重新调度时,重新计算KV缓存,延迟显著低于原始延迟,解码时生成的token可以与原始用户提示连接作为新的提示,所有位置的KV缓存可以在一次提示阶段迭代中生成。
交换和重计算的性能取决于CPU、RAM和GPU内存之间的带宽以及GPU的计算能力。
6. 分布式执行
vLLM支持Megatron-LM风格的张量模型并行策略,遵循SPMD执行调度,线性层划分以执行逐块矩阵乘法,并通过allreduce操作同步中间结果。
具体来说,注意算子在注意头维度上被分割,每个SPMD过程负责多头注意中的注意头子集,每个模型分片处理相同的输入token集合,在同一位置需要KV缓存。
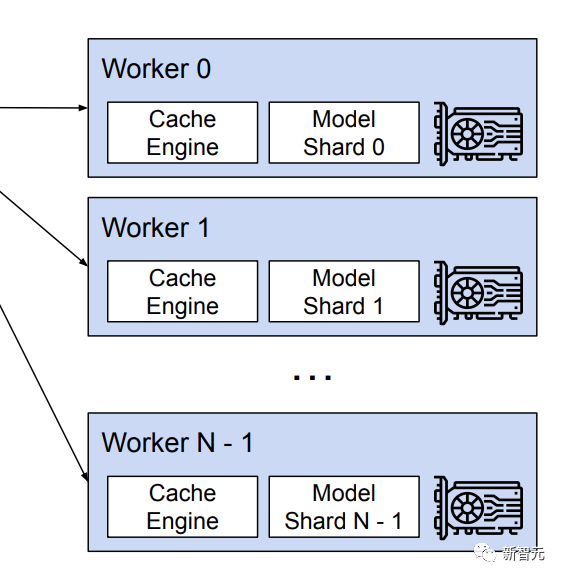
不同的GPU worker共享管理器,从逻辑块到物理块的映射,调度程序为每个输入请求提供的物理块来执行模型;每个GPU工作线程具有相同的物理块id,但一个工作线程仅为其相应的注意头存储KV缓存的一部分。
在每一步中,调度程序为批处理中的每个请求准备带有输入token id的消息,以及每个请求的块表;
调度程序广播该控制消息给GPU worker,使用输入token id执行模型;在注意力层,根据控制消息中的块表读取KV缓存;执行过程中,将中间结果与all-reduce通信原语同步,无需调度程序协调。
最后,GPU worker将该迭代的采样token发送回调度器。
基础采样
