设想一下,医生写几句话来描述一种专门用于治疗患者的药物,AI 就能自动生成所需药物的确切结构。这听起来像是科幻小说,但随着自然语言和分子生物学交叉领域的进展,未来很有可能成为现实。传统意义上讲,药物创造通常依靠人工设计和构建分子结构,然后将一种新药推向市场可能需要花费超过 10 亿美元并需要十年以上的时间。
近来,人们对使用深度学习工具来改进计算机药物设计产生了相当大的兴趣,该领域通常被称为化学信息学。然而,其中大多数实验仍然只关注分子及其低级特性,例如 logP,辛醇 / 水分配系数等。未来我们需要对分子设计进行更高级别的控制,并通过自然语言轻松实现控制。
来自伊利诺伊大学厄巴纳-香槟分校和 Google X 的研究者通过提出两项新任务来实现分子与自然语言转换的研究目标:1)为分子生成描述;2)在文本指导下从头生成分子。

论文地址:http://blendeR.cs.illinois.edu/papeR/Molt5.pdf
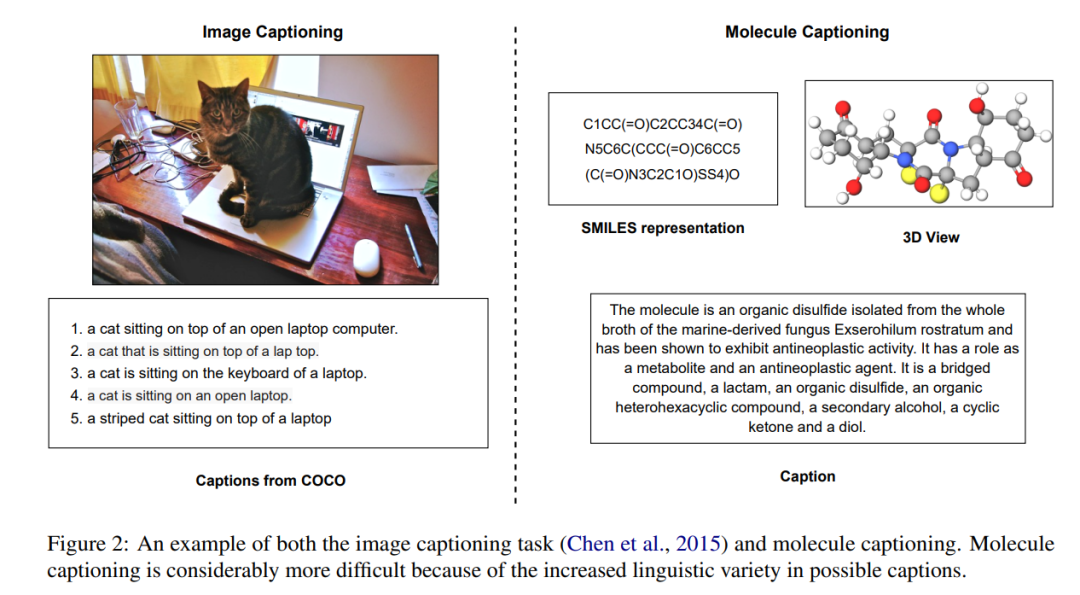
如下图所示,文本指导分子生成任务是创建一个与给定自然语言描述相匹配的分子,这将有助于加速多个科学领域的研究。
在多模态模型领域,自然语言处理和计算机视觉 (V+L) 的交叉点已被广泛研究。通过自然语言实现对图像的语义级控制已取得一些进展,人们对多模态数据和模型越来越感兴趣。
该研究提出的分子 – 语言任务与 V+L 任务有一些相似之处,但也有几个特殊的难点:1)为分子创建注释需要大量的专业知识,2)因此,很难获得大量的分子 – 描述对,3) 同一个分子可以具有许多功能,需要多种不同的描述方式,这导致 4) 现有评估指标(例如 BLEU)无法充分评估这些任务。
为了解决数据稀缺的问题,该研究提出了一种新的自监督学习框架 MolT5(MoleculaR T5),其灵感来源于预训练多语言模型的最新进展。
此外,为了充分评估分子描述或生成模型,该研究提出了一个名为 Text2Mol 的新指标。
研究人员可以从互联网上抓取大量的自然语言文本。例如,RaFFel et al. (2019) 构建了一个 CoMMon CRawl-based 数据集,该数据集包含超过 700GB、比较干净的自然英语文本。另一方面,我们也可以从 ZINC-15 等公共数据库中获取超过 10 亿个分子的数据集。受近期大规模预训练进展的启发,该研究提出了一种新的自监督学习框架 MolT5(MoleculaR T5),其可以利用大量未标记的自然语言文本和分子字符串。
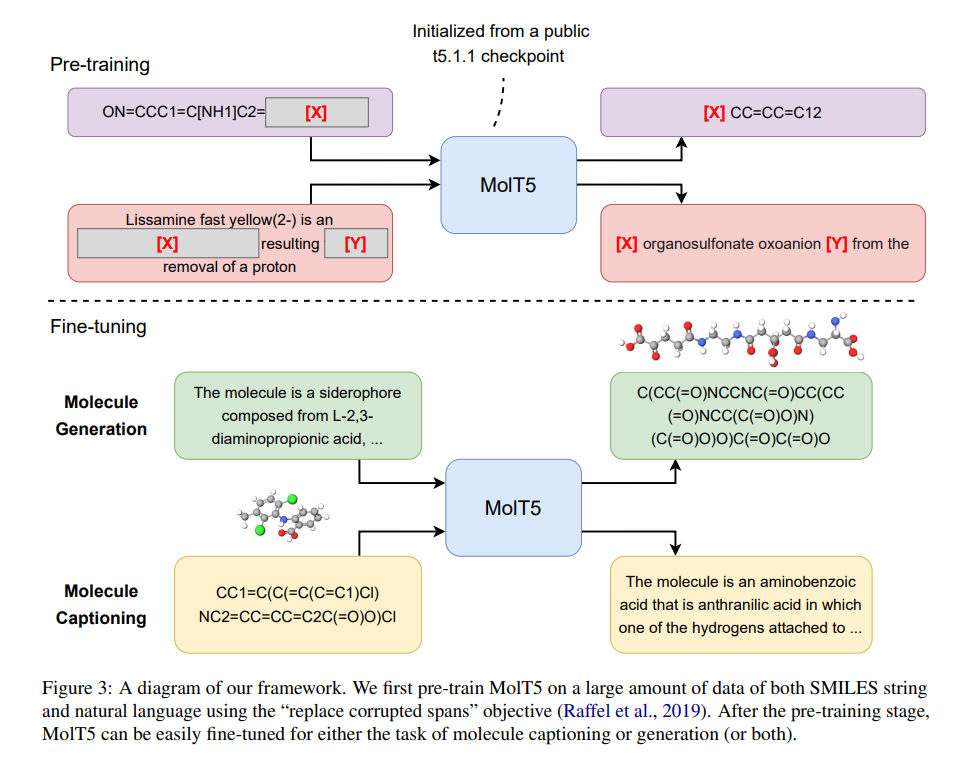
分子(例如,用 SMILES 字符串表示)可以被认为是一种具有非常独特语法的语言。直观地说,该研究的预训练阶段本质上是在来自两种不同语言的两个单语语料库上训练一个语言模型,并且两个语料库之间没有明确的对齐方式。这种方法类似于 MBERT 和 MBART 等多语言语言模型的预训练方式。由于 MBERT 等模型表现出出色的跨语言能力,该研究还期望使用 MolT5 预训练的模型对文本 – 分子翻译任务有用。
预训练之后,可以对预训练模型进行微调,以用于分子描述(Molecule captioning)或生成。
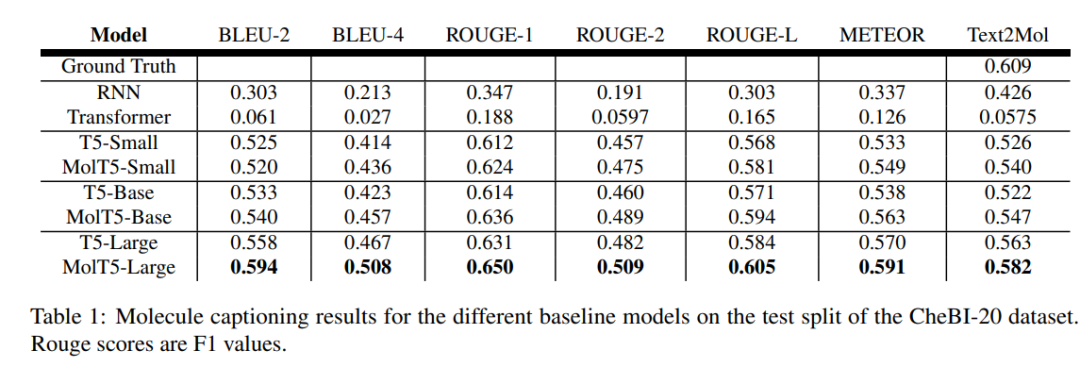
下表 1 为分子描述测试结果,研究发现,大的预训练模型在生成逼真语言来描述分子方面,T5 或 MolT5 比 TRansfoRMeR 或 RNN 要好得多。
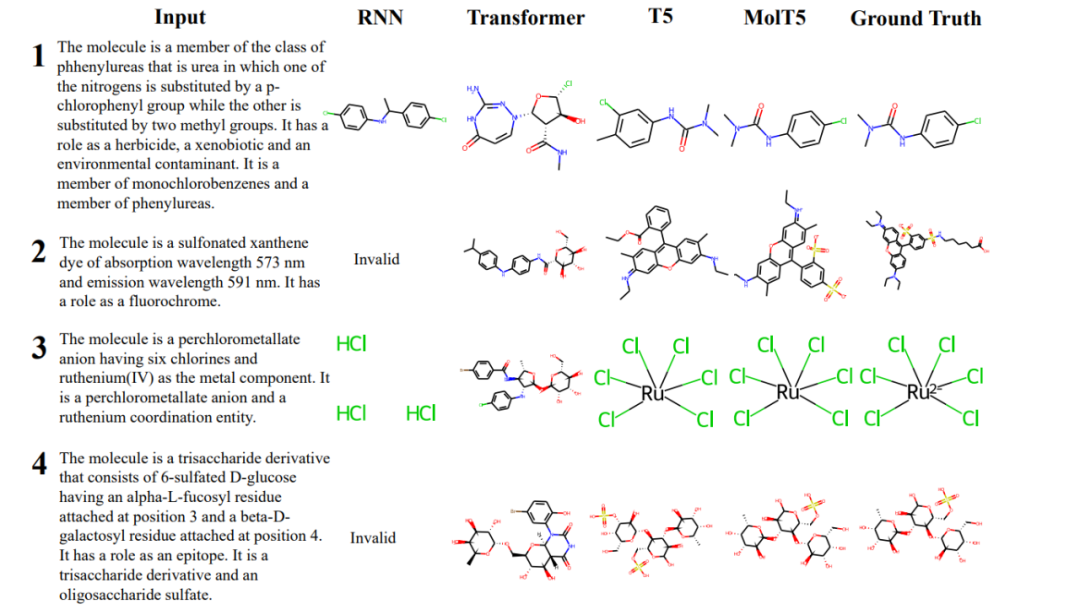
下图 5 显示了几个不同模型输出示例。

通常 RNN 模型在分子生成方面优于 TRansfoRMeR 模型,而在分子描述任务中,大型预训练模型比 RNN 和 TRansfoRMeR 模型表现得更好。众所周知,扩展模型大小和预训练数据会导致性能显着提高,但该研究的结果仍然令人惊讶。
例如,一个默认的 T5 模型,它只在文本数据上进行了预训练,能够生成比 RNN 更接近真值的分子,而且通常是有效的。并且随着语言模型规模的扩展,这种趋势持续存在,因为具有 770M 参数的 T5-laRge 优于具有 60M 参数的专门预训练的 MolT5-SMall。尽管如此,MolT5 中的预训练还是略微改善了一些分子生成结果,尤其是在有效性方面的大幅提升。
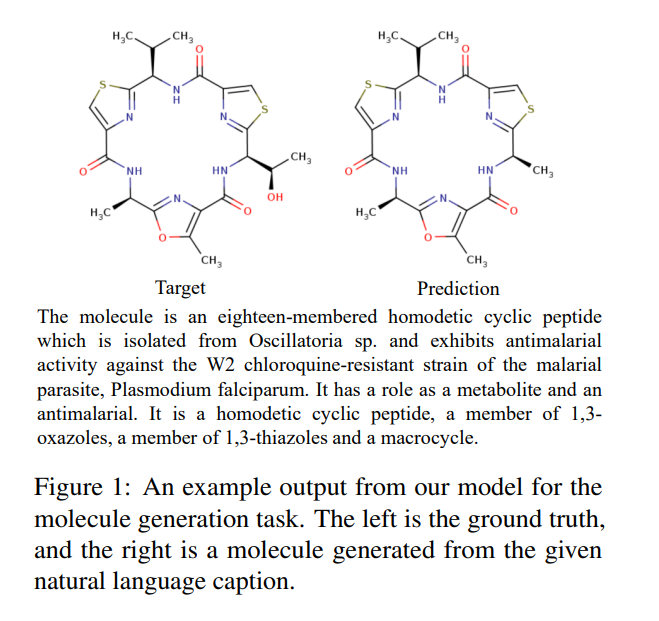
下图 4 显示了模型的结果,并且按输入描述对其进行编号。实验发现,与 T5 相比,MolT5 能够更好地理解操作分子的指令。